








































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































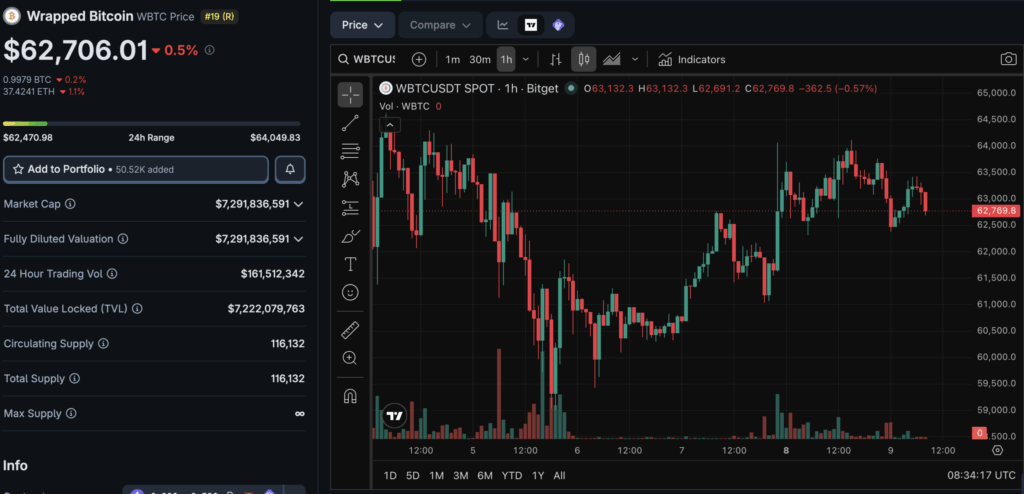

















































































































































































































































































































































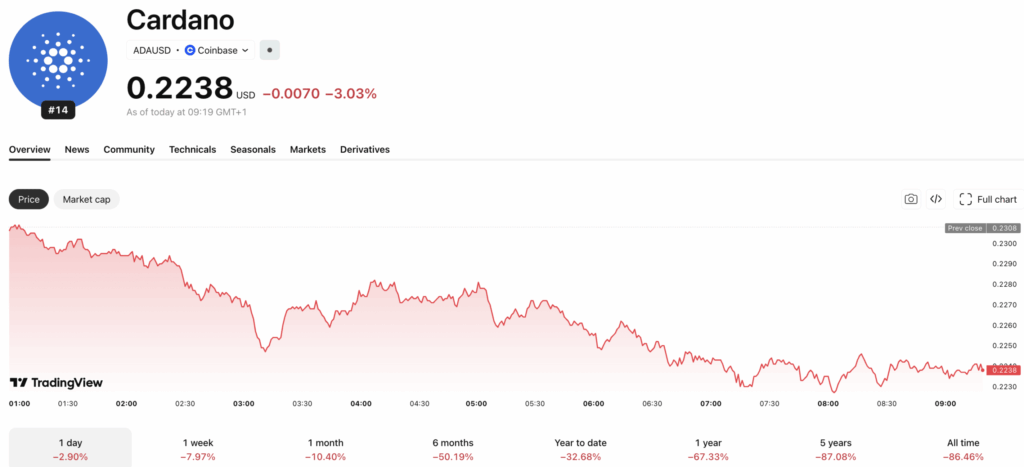


























































































































































































































































































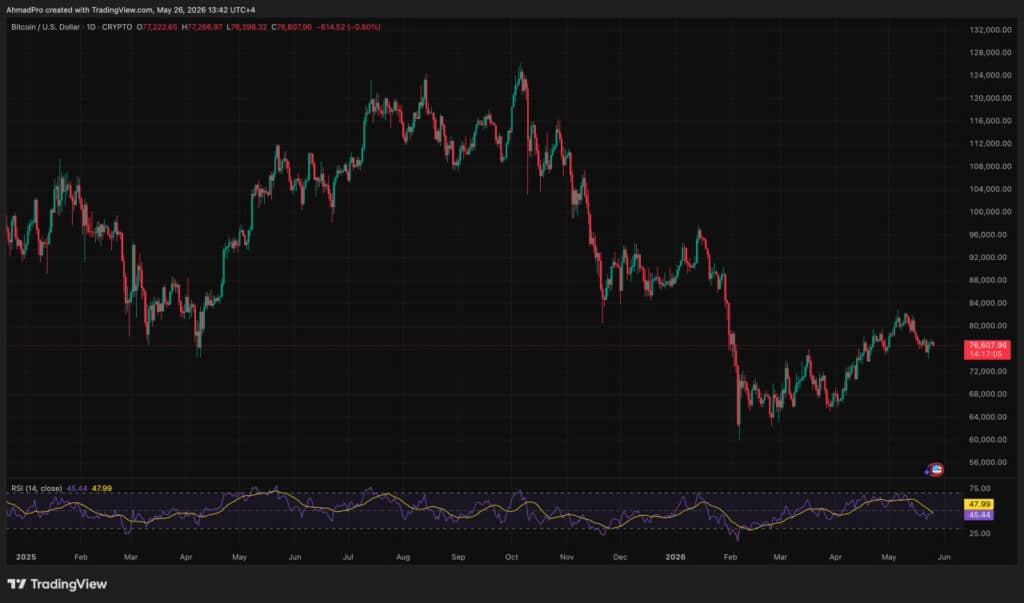























































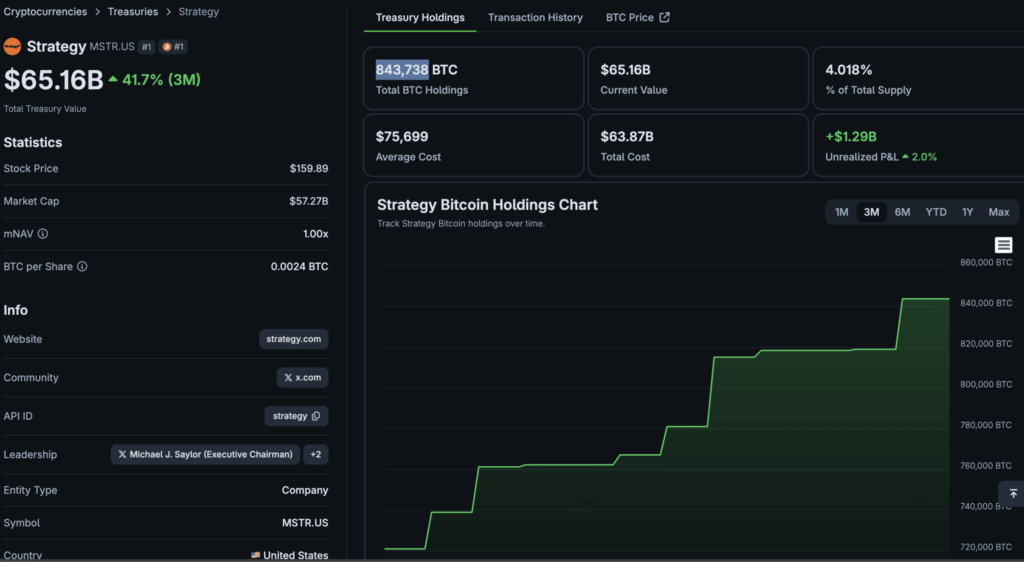




















































































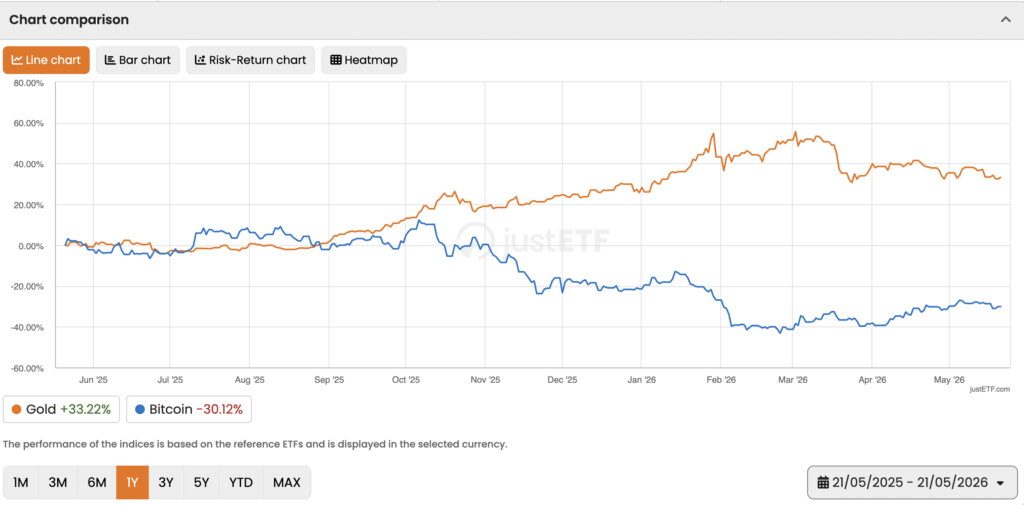
























































































































































































































































































































































































































































































Someone Tested a 1997 Processor and Proved That Just 128 MB of RAM Is Enough to Run AI – Bitcoin News
Key Takeaways
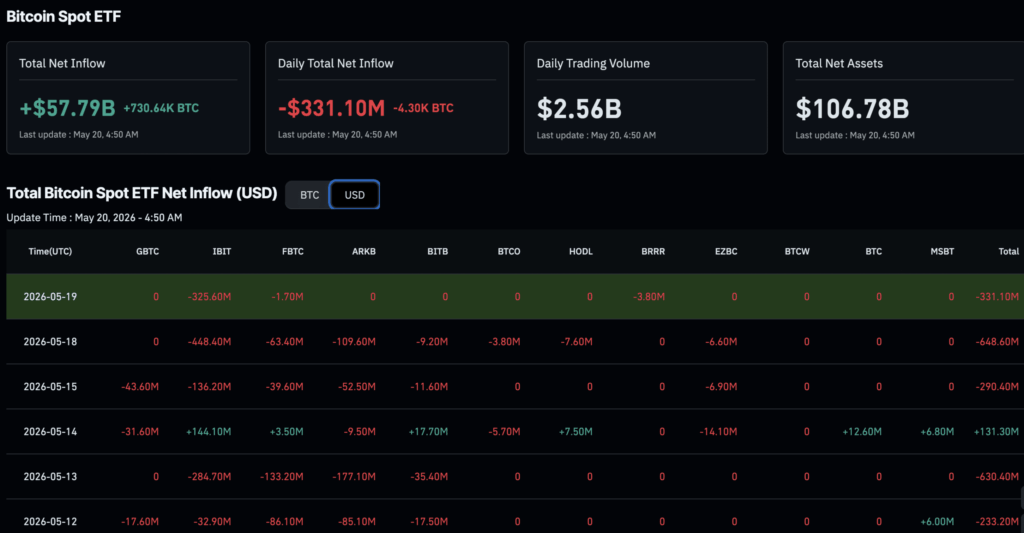
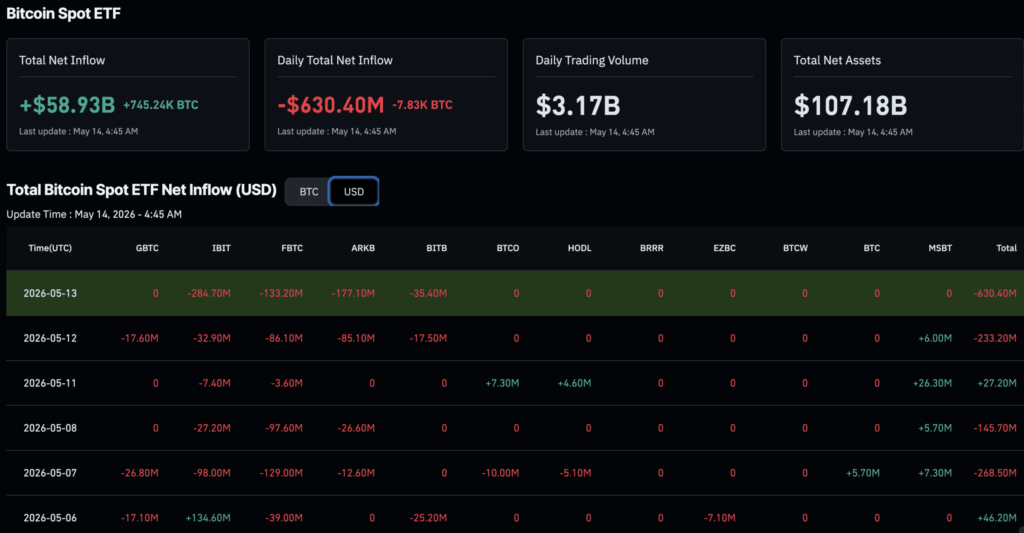
- EXO Labs ran Llama 2 on a 1997 Pentium II with just 128 MB of RAM.
- BitNet used -1, 0, and 1 weights to cut AI memory and compute demands.
- Nvidia-era AI costs face pressure as EXO Labs pushes software-first efficiency.
EXO Labs just taught a Pentium II with 128 MB of RAM a new trick: run a trimmed Llama 2 model, slowly but surely. The team leaned on BitNet, a ternary-weight approach that pares neural math down to -1, 0, and 1, squeezing modern AI through a 1997 bottleneck. The result doesn’t dethrone your GPU rig, but it pokes holes in the reflex that more silicon is the only path forward. If software can stretch this far on museum-grade hardware, the next wave of AI efficiency might start with smarter code, not pricier chips.
Running AI on a relic of the past
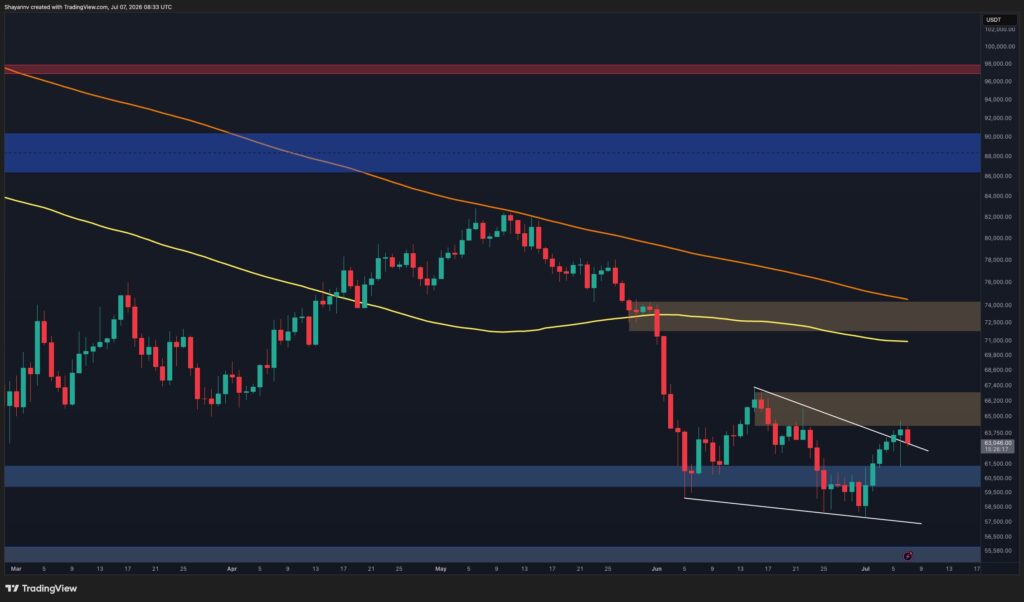
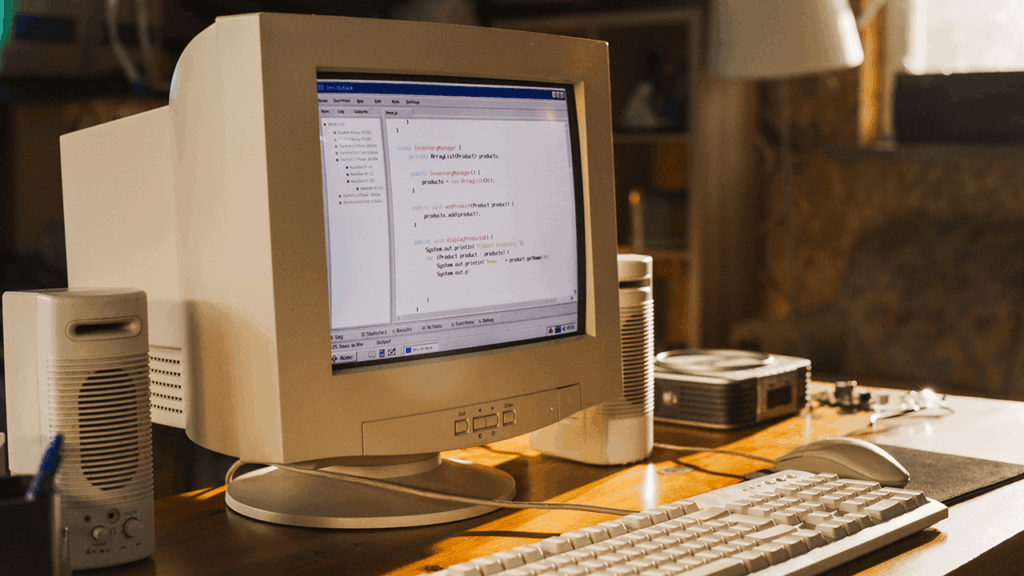
There is something quietly satisfying about watching old silicon do new tricks. The research group at EXO Labs showed a modern language model running on a beige-box PC from 1997, powered by a Pentium II and just 128 MB of RAM. The model was a slimmed variant of Llama 2, and the demo challenged a simple assumption: more AI always needs more machine.
The ingenuity behind BitNet
The secret sauce is a software structure called BitNet. Instead of high-precision math, BitNet pushes neural networks to work with ternary weights, specifically −1, 0, and 1. That slashes compute and memory pressure to the bone. Output arrived slowly, word by word, but it arrived. The point was not speed, it was feasibility on severely constrained hardware.
A marriage of old and new technology
There is a clear contrast here. The 1990s mindset prized efficiency, because every cycle counted. Today’s AI stacks assume abundant GPUs. This project meets in the middle, showing that careful quantization, pruning, and data layout can offset brute force. It also nods to sustainability debates in the U.S., where the energy footprint of training and inference is drawing more scrutiny from policymakers and cloud buyers.
Why this matters for developers and buyers
For developers, the lesson is simple: start with constraints. If a ternary-weight network can survive on a Pentium II, it can certainly thrive on a midrange laptop, an edge gateway, or even a microserver tucked in a retail store. That could broaden on-device inference, reduce latency, and trim cloud bills. For enterprise buyers, software-first efficiency can translate to fewer GPUs and less capex.
What it does not claim
This is not a bid to replace data center training or dethrone high-end accelerators from Nvidia. The demo ran a pared-back model, and the responsiveness would not satisfy heavy production use. Still, it is a useful counterexample. Tooling that treats precision as optional and memory as scarce can open doors for civic tech, classrooms, and startups that lack a cluster but still want capable models.
The bigger takeaway is cultural. Progress in AI does not only belong to those with the most silicon. It also belongs to those who squeeze the most out of it. Indeed, software discipline can be as impactful as a new chip tape-out when it gets models closer to people, places, and budgets that were previously out of reach.